
Signal from Noise
Quantum creates uncertainty, uncertainty creates risk, and code turns that risk into random variables you can measure and simulate. At the fundamental level we rely on random number generators for encryption and trustworthy sampling, including physical entropy sources like lava-lamp RNGs.
See the conceptual chain in Quantum vs Classical and Plain Language Guide.
Game Theory & Econometrics: Studying the Universe as a Canvas of Strategy
Explore Alternative Base ArithmeticClassical physics often treats the universe as perfectly deterministic—like a clockwork mechanism where every position and momentum strictly dictates the next. But studying the universe, particularly systems rich with complex interactions or market uncertainties, requires moving past rigid determinism. It becomes part art, part science.
The Elegance of Econometrics
Econometrics allows us to observe this non-deterministic universe through the lens of mathematical statistics. Instead of declaring \( y = mx + b \) natively, we acknowledge the inherent noise in reality:
\[ \mathbf{Y} = \mathbf{X}\boldsymbol{\beta} + \boldsymbol{\epsilon} \]
Here, the vector \(\boldsymbol{\epsilon}\) elegantly captures everything we cannot see or predict. Econometrics embraces uncertainty, empowering analysts to extract genuine geometric patterns out of stochastic chaos using robust mathematical deduction rather than guessing.
Game Theory: The Calculus of Strategy
If probability shows us what might happen, Game Theory simulates what actors will choose to make happen. It is not about modeling the entire infinite, chaotic set of all possible events; instead, it mathematically winnows the universe down to only the most strategically viable scenarios.
Consider the famous Monty Hall problem. At first glance, a game with three doors appears to be a simple uniform distribution of \(1/3\) probability each. But game theory and Bayesian updating reveal that the space is non-binary. When the host—an actor with knowledge of the system—opens an empty door, the probabilities do not reset to a $50/50$ binary coin toss. The geometry of the probability space collapses, shifting a \(2/3\) probability mass to the remaining unopened door. Strategic viability dictates that changing your choice is mathematically superior.
Consider two rational players optimizing their payoffs \( \pi_1 \) and \( \pi_2 \) based on their continuous strategy sets \( x \) and \( y \). They are not blindly feeling around for an edge; they calculate their marginal utility vectors using differential calculus:
\[ \frac{\partial \pi_1(x, y)}{\partial x} = 0 \quad \text{and} \quad \frac{\partial \pi_2(x, y)}{\partial y} = 0 \]
The intersection of these partial derivatives represents a Nash Equilibrium—a stable state of the universe where no individual can unilaterally improve their position. By combining linear algebra (payoff matrices) and calculus (gradient optimization), Game Theory cuts through the noise of irrational behavior and highlights the inevitable strategic paths.
Your Right to the Underlying Math
As a student of reality, you deserve to look at the equations under the hood. Mathematical optimization and matrix mechanics are not just academic abstractions; they are the literal source code for understanding how markets balance, how networks secure themselves, and how complex systems stabilize. Armed with linear algebra and calculus, you no longer need to accept narrative myths about how systems operate—you have the mathematical tools to prove it yourself.
Topology & Logic: Breaking the Intuitive Universe
When we equip ourselves with mathematics, we quickly discover that our intuition about reality is heavily colored by our limited, localized perspective. However, logic and mathematical topology allow us to peer outside these limitations to observe phenomena that defy conventional human expectations.
The Unexpected Tiger: A Riddle Defying Logic
Consider the Unexpected Tiger Paradox. A king tells a prisoner, "You will be chased by a tiger at noon on one day next week (Monday through Friday), but it will be a complete surprise." The prisoner deduces that the tiger cannot come on Friday, because if it hasn't come by Thursday, Friday would be expected—and therefore not a surprise. By eliminating Friday, he then eliminates Thursday, all the way back to Monday, concluding the tiger can never arrive. Yet, when the tiger arrives on Wednesday, the prisoner is completely surprised! It highlights a fundamental collapse in self-referential logic and epistemic reasoning—a point where ostensibly rigorous deduction creates a crippling blind spot.
Möbius Loops & The Angle of Topology
Our brains natively understand spaces as having distinct "insides" and "outsides," or "tops" and "bottoms." But mathematical topology asks us to discard this Euclidean prejudice. A Möbius strip is a surface with only one continuous side and one continuous boundary edge. If you trace a line along its center, you will eventually traverse the "bottom" and return to the start without ever lifting your pen or crossing an edge. From a topological angle, it proves that local flatness (what an ant perceives while walking on it) does not dictate global structure. Just like the universe itself, the local geometry we experience daily masks a drastically different, mind-bending global topology.
Flatland: The Geometry of Perspective
To truly grasp how limited our perception is, consider Edwin A. Abbott's brilliant 1884 science fiction story Flatland. It describes a universe of exactly two dimensions, populated by geometric shapes who can only see along lines. When a three-dimensional Sphere visits Flatland, it passes through their 2D plane. To the Flatlanders, the Sphere appears as a point that mysteriously grows into a larger circle, shrinks, and vanishes—a completely inexplicable miracle in 2D physics. The Sphere tries to explain "up" and "down", but the 2D beings cannot comprehend a direction outside their plane. Through mathematics, we are like the Flatlanders attempting to reason about higher dimensional spaces (like string theory's 11 dimensions or the unbounded Hilbert spaces of quantum mechanics). We may not be able to easily visually "see" them, but we can rigorously calculate their properties.
Inside DataFest: The Ultimate College Coding Challenge
Imagine this.... a massive coding competition meets Shark Tank. Now add AI, Business Intelligence, and a room full of students cracking it wide open. Yeah, welcome to DataFest. This isn't just about code, it's about real problems, real data, and real solutions that slap. The energy? Electric. The mission of DataFest is to expose undergraduate students to challenging questions with immediate real-world significance that can be addressed through data analysis. By working in teams, students with varying skill sets will combine their efforts and expand their collective data analysis horizons. Interaction among students, as well as with outside consultants, will promote the sense that data analysis is a dynamic, engaging, and vibrant part of our society, as well as a realistic, practical, and fun career path.
The Matrix is a Movie About Data Science
The Matrix is all around us. When not bending spoons or doing kung fu, this is a fantastic movie about data.
Learn how to use open-source software called Scilab for linear algebra.
Code: https://github.com/sdcastillo/TheMatrixML
Download Scilab: https://www.scilab.org/download
Celebrating Pi Day: Exploring the Infinite Beauty of Mathematics
Happy Pi Day! March 14th is a celebration of π and the math that ties geometry, calculus, and patterns together. Plus, it is a great excuse to enjoy a slice of pie.
College path paper on Pi (MATH 233, UMass Amherst): Overleaf paper
Predictive Analytics with H2O.ai - Build Interactive ML Apps in 2 hours with ChatGPT O1
Unlock the power of predictive analytics with the H2O AI library. This autopilot ML system fits multiple models, runs ensembles, and selects the optimal model based on your settings.
You can run it with R Shiny, with Java in the stack. I used ChatGPT O1 over a few hours to build an end-to-end predictive modeling app.
Code: https://github.com/sdcastillo/Modeling-Project/blob/master/README.md
AI Foundation Models - Reliable & Secure Generative AI (AWS Bedrock)
Amazon Bedrock is a service for building foundation models with easy scaling and customization, focused on reliable and secure generative AI via model selection, tuning, and guardrails.
Highlights: model selection, guardrails for safety, and parameter control for consistent outputs.
Conversational AI with Documents (Claude 3 Sonnet)
AWS Bedrock's chat-with-document feature analyzes complex technical documents, extracts AIC values, and distinguishes Poisson vs Gamma GLM models without manual copy-pasting.
Keywords: AWS Bedrock, Claude AI, document analysis, GLM, AIC, actuarial modeling, data science automation.
Review of the New Chat GPT-4 Omni - First Impressions
Faster and more conversational, but still not AGI. The legal-document test shows GPT-4 Omni can be verbose and miss important clauses.
Date: Aug 22, 2024. Tags: ChatGPT, GPT-4o, LLM, GenAI, OpenAI.
Ideas about Terraforming Mars
A market-driven approach to Mars terraforming: incentivize companies to increase O2 and temperature, reversing Earth's greenhouse problem for the red planet.
Tags: renewable future, space, clean energy, Mars, NASA, SpaceX.
The Essentials of Predictive Modeling with Howard Friedman, PhD
With Howard Friedman, PhD, Coloumbia University, data scien Typical Data Science Playbook Elements Can Include: Data Strategy Development and Project Prioritization Model Improvements/Optimization Customer Segmentation: Applicable to B-B and B-C Profitability Analysis: Product-level, Customer-level Site Selection: Operations Metrics Selection: Factors drive quality, profitability, efficiency, etc. Risk Modeling/Failure Modeling: Product-level, Customer-level, Site-level Forecasting: Incorporating internal and external data Marketing Optimization: Automation Opportunities: Human Resources Modeliing: Modeling success, attrition, etc.
The Essentials of Predictive Modeling with Dave Snell, FSA, MAA and Ahmed Rasheed
📚 Ready to conquer Exam PA? Join our latest webinar for an enlightening session on machine learning and strategic study tips. Led by experts Dave Snell and Ahmed Rasheed, this webinar is your gateway to mastering predictive analytics. Explore unique picture-definition associations to enhance your recall of statistical definitions. Jump to the main content at 11:59 for a focused review. It is important to consider whether the business problem is to gain inference about data or to make predictions without needing to understand the model.
Future Role of AI with the UMass Amherst Actuarial Science Students
📚 Sam Castillo, a UMass Amherst alumnus, discusses his non-traditional actuarial career, the integration of AI in risk assessment, and strategies for exam preparation. He emphasizes building a strong resume, understanding actuarial designations, and the importance of interpersonal skills, while also reflecting on career satisfaction and opportunities for international work.
- 00:00:00 - 00:08:12 Sam Castillo's Actuarial Journey and Exam Preparation
- 00:08:12 - 00:16:59 Building Experience and Marketing Skills for Actuarial Science Students
- 00:16:59 - 00:19:22 Actuarial Profession Perks and Opportunities
- 00:19:22 - 00:27:27 The Impact of AI in Actuarial Science and Personal Career Reflections
- 00:27:27 - 00:37:21 Actuarial Science vs. Statistics and Exam Pathways
- 00:37:21 - 00:45:03 Learning R and Python for Actuarial Science and Career Advice
- 00:45:03 - 00:50:22 The Importance of Actuarial Exams and Career Progression
- 00:50:22 - 00:54:07 Career Path and Professional Development in Actuarial Science
Powerful Workflow Automation Tools - Database with LLMs
Build limitless AI-powered automations using emails to custom prompts to OpenAI to Supabase to Notion and more.
Step-by-step: custom email trigger to OpenAI API to Supabase storage to Notion/Slack to perfect audit trail.
Start Here: Complete Cyber Security Introduction for 2025
Master cyber security basics in 20 minutes, free tools, ethical hacking, careers.
Cyber Security Topics Overview





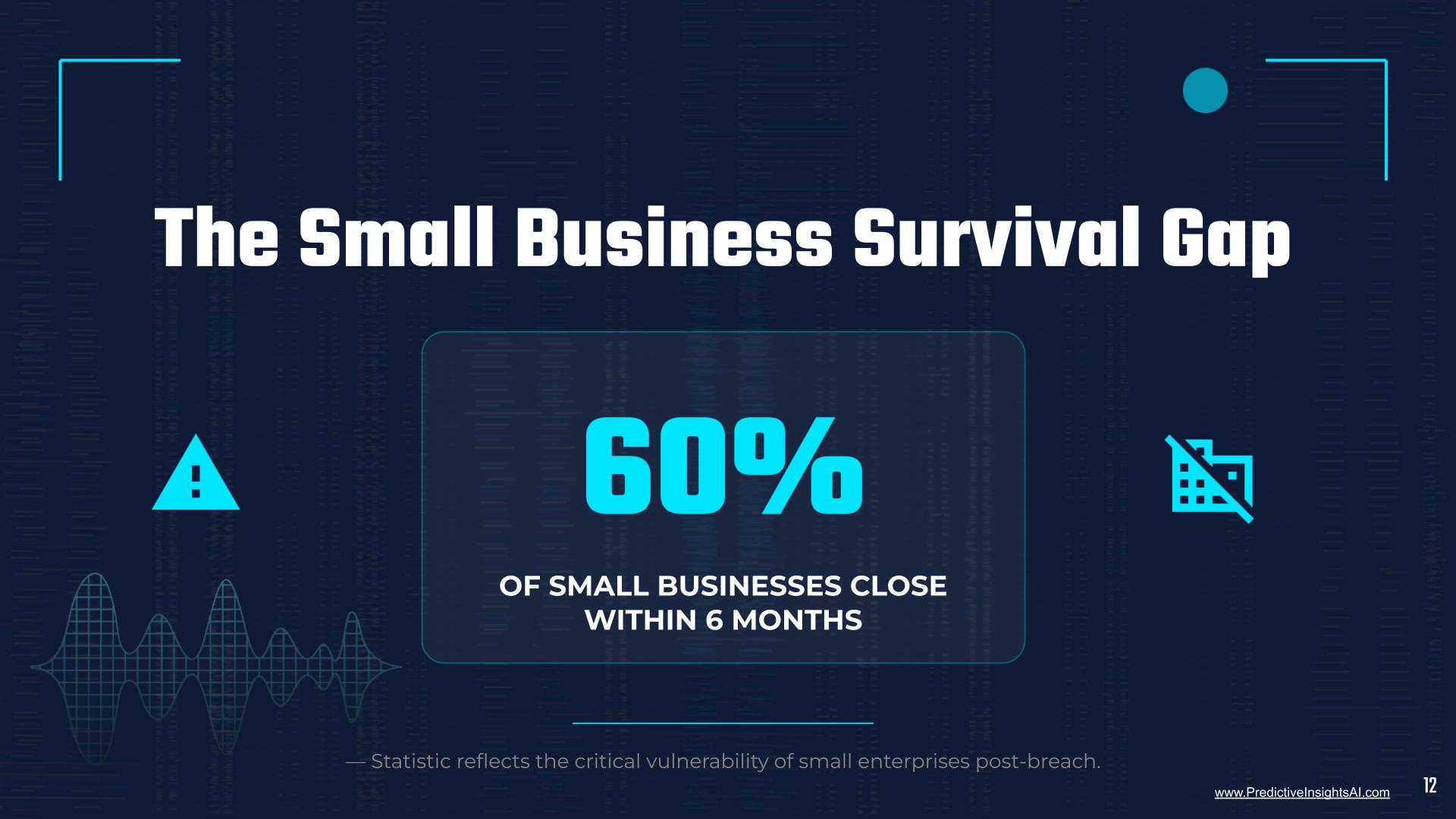



Internal Local Area Networks
Run Mistral AI and Large Language Models fully offline on your own secure LAN — zero cloud, zero data leaks.
Physicists and Scientists Hold the Key to AI’s Future-Not Just the Singularity
Unlock the secrets of tomorrow with our deep dive into the Future of AI! In this video, we explore how artificial intelligence is transforming industries, reshaping our daily lives, and what breakthroughs you can expect in the coming years. From advancements in machine learning and robotics to ethical considerations and the rise of generative AI, discover what’s next for technology and humanity.
Using Cursor to create Histograms Fast with GitHub Copilot
Supercharge your data analysis workflow with this step-by-step guide on Using Cursor to Create Histograms Fast with GitHub Copilot! In this video, you’ll learn how to harness the power of Cursor AI-a cutting-edge code editor-and GitHub Copilot to quickly generate Python code for histograms and exploratory data analysis (EDA).
AI, ML, and Predictive Analytics— What’s the Difference?
Mastering GLM Link Functions: A Comprehensive Guide
How Robots Write Code with Human Supervisors
This page was assembled with automated assistance: generative tooling produced structure and text, which were reviewed and emitted as static HTML. In other words, the site itself serves as a small example of code that helps author more code. AI for Not Bad.
This page was assembled with automated assistance: generative tooling produced structure and text, which were reviewed and emitted as static HTML. In other words, the site itself serves as a small example of code that helps author more code. We always keep a human in the loop.
Abstractly, denote the human editor as \(H\) and the generative model as \(G\). Let \(x\) be an initial specification and \(y\) the final HTML. The interaction can be seen as an alternating minimization over drafts \(y_t\): \[ y_{t+1} = \operatorname*{arg\,min}_{y} \Big( \mathcal{L}_\text{spec}(y \mid x) + \mathcal{L}_\text{style}(y) + \mathcal{L}_\text{error}(y) \Big), \] with updates produced by either \(G\) or \(H\): \[ y_{t+1} = \begin{cases} G(y_t,x,\xi_t) & \text{with probability } p_G, \\ H(y_t,x) & \text{with probability } 1-p_G, \end{cases} \] where \(\xi_t\) captures model stochasticity. Convergence is reached when successive edits satisfy a small-difference condition, e.g. \[ d(y_{t+1},y_t) < \varepsilon, \] for a suitable distance metric \(d\) on documents.
Deep dive: a tiny quantum circuit in code and math
Here is a minimal example of preparing a Bell state using Python-style pseudocode with a Qiskit‑like API, plus the matching math.
# Pseudocode using a Qiskit-like API
from qiskit import QuantumCircuit
qc = QuantumCircuit(2, 2) # 2 qubits, 2 classical bits
# 1. Put qubit 0 into a superposition
qc.h(0)
# 2. Use it as control for a CNOT on qubit 1
qc.cx(0, 1)
# 3. Measure both qubits
qc.measure(0, 0)
qc.measure(1, 1)Mathematically, in the \(|00\rangle,|01\rangle,|10\rangle,|11\rangle\) basis:
- Start in \(|00\rangle\).
- Apply \(H\) to the first qubit: \[ H|0\rangle = \tfrac{1}{\sqrt{2}}(|0\rangle + |1\rangle), \] so the joint state becomes \[ |\psi_1\rangle = \tfrac{1}{\sqrt{2}}(|00\rangle + |10\rangle). \]
- Apply CNOT with qubit 0 as control and qubit 1 as target: \[ \text{CNOT}|00\rangle = |00\rangle, \quad \text{CNOT}|10\rangle = |11\rangle. \] Therefore \[ |\psi_2\rangle = \tfrac{1}{\sqrt{2}}(|00\rangle + |11\rangle) = |\Phi^+\rangle. \]
When you measure both qubits in the computational basis, you get:
- \(P(00) = 1/2\)
- \(P(11) = 1/2\)
- \(P(01) = P(10) = 0\)
This is “maximal entanglement” in its simplest form.
Minimal meta-programming sketch
// Pseudocode for a self-improving loop
population = initialize_programs()
while (time < budget):
for prog in population:
result = execute(prog, tests)
score = measure(result)
log(result, score)
models = fit_surrogates(log) // learn to predict score from program features
proposals = propose(models) // synthesize or mutate new programs
population = select(population, proposals, log) // keep better, diverse candidates
if converged(population): break
deploy(best(population))
Let the population at iteration \(t\) be \(\mathcal{P}_t = \{\theta_t^{(1)},\dots,\theta_t^{(N)}\}\), and let each candidate have a score (fitness) \(F(\theta)\). The selection step can be modeled by a softmax (Boltzmann) sampling distribution \[ P_t(\theta) = \frac{\exp\big(\beta_t F(\theta)\big)}{\sum_{\theta' \in \mathcal{P}_t} \exp\big(\beta_t F(\theta')\big)}, \] with inverse temperature \(\beta_t\) controlling selection pressure. Proposals (mutations or synthesized programs) \(\tilde{\theta}\) are drawn from a proposal kernel \(q_t(\tilde{\theta} \mid \theta)\), so the expected update of the population distribution is \[ p_{t+1}(\tilde{\theta}) = \sum_{\theta} P_t(\theta)\, q_t(\tilde{\theta} \mid \theta). \] Convergence of the loop can be expressed via a stopping condition such as \[ \operatorname{Var}_{\theta \sim p_t}[F(\theta)] < \delta \quad \text{or} \quad \max_{\theta \in \mathcal{P}_t} F(\theta) - \max_{\theta \in \mathcal{P}_{t-k}} F(\theta) < \epsilon, \] for some window size \(k\) and tolerances \(\delta, \epsilon\).
Hierarchical graph of matter and interactions
Universe
└─ Quantum fields
├─ Fermion fields (matter)
│ ├─ Quarks (color charge: red/green/blue)
│ │ ├─ Flavors: up, down, charm, strange, top, bottom
│ │ └─ Bound states (hadrons)
│ │ ├─ Baryons (3 quarks)
│ │ │ ├─ Proton: u u d
│ │ │ ├─ Neutron: u d d
│ │ │ └─ Antibaryons (3 antiquarks)
│ │ │ └─ Antiproton: ū ū d̄
│ │ └─ Mesons (quark + antiquark)
│ └─ Leptons
│ ├─ Electron, Muon, Tau
│ └─ Neutrinos (three types) + corresponding antiparticles (e.g., positron)
├─ Boson fields (interaction carriers)
│ ├─ Gluons (strong interaction, SU(3) color)
│ ├─ Photon (electromagnetic, U(1))
│ ├─ W± and Z⁰ (weak interaction)
│ └─ Gravitational quantum (graviton, hypothetical)
└─ Scalar field associated with electroweak symmetry breaking
└─ Scalar boson (mass-generating excitation)
Composite structures
└─ Atomic nucleus: protons + neutrons (held by residual strong force)
├─ Atoms: nucleus + electron cloud (quantized orbitals)
├─ Molecules: atoms bound via electromagnetic interaction
└─ Condensed phases: solids, liquids, gases, plasmas, exotic matter
“Matter” typically denotes fermions and their composites. Gauge bosons (such as gluons) mediate interactions and are included for completeness.
In the Standard Model, the fundamental fields can be written as a Lagrangian density \(\mathcal{L}_\text{SM}\) of the form \[ \mathcal{L}_\text{SM} = -\frac{1}{4} \sum_{a} F_{\mu\nu}^a F^{a\,\mu\nu} + \sum_{f} \bar{\psi}_f\big(i\gamma^\mu D_\mu - m_f\big)\psi_f + (D_\mu \phi)^\dagger(D^\mu \phi) - V(\phi) + \mathcal{L}_\text{Yukawa}, \] where \ F_{\mu\nu}^a = \partial_\mu A_\nu^a - \partial_\nu A_\mu^a + g f^{abc} A_\mu^b A_\nu^c \\ encodes the gauge bosons (gluons, \(W^\pm, Z^0\), photon), \(\psi_f\) are fermion fields (quarks and leptons), \(\phi\) is the Higgs scalar field, and \(D_\mu = \partial_\mu - i g A_\mu^a T^a\) is the gauge-covariant derivative.
Color-charged quarks \(q\) interact via the SU(3) gauge field \(G_\mu^a\) with coupling constant \(g_s\), described by \[ \mathcal{L}_\text{QCD} = \bar{q}\big(i\gamma^\mu D_\mu - m_q\big)q - \frac{1}{4} G_{\mu\nu}^a G^{a\,\mu\nu}, \] where \(D_\mu = \partial_\mu - i g_s T^a G_\mu^a\) and \(G_{\mu\nu}^a\) has the same non-Abelian structure as \(F_{\mu\nu}^a\) above. Bound states such as protons and neutrons are color-singlet combinations of three quarks (baryons), while mesons are quark–antiquark pairs \(q \bar{q}\), consistent with overall color neutrality.
Leptons (electron \(e\), muon \(\mu\), tau \(\tau\) and their neutrinos \(\nu_e, \nu_\mu, \nu_\tau\)) couple to the electroweak SU(2)\(_L\)\timesU(1)\(_Y\) gauge fields. After electroweak symmetry breaking, the Higgs field acquires a vacuum expectation value \[ \langle \phi \rangle = \frac{1}{\sqrt{2}} \begin{pmatrix}0 \\ v \end{pmatrix}, \qquad v \approx 246~\text{GeV}, \] which generates fermion and weak boson masses through Yukawa terms \(y_f \bar{\psi}_f \phi \psi_f\) and gauge interactions, while leaving the photon massless.
Composite structures are organized hierarchically. A nucleus with \(Z\) protons and \(A-Z\) neutrons has baryon number \(B = A\) and charge \(Q = Z e\). An atom adds \(Z\) electrons, leading to a many-body Hamiltonian \[ H = \sum_{i=1}^{Z} \bigg( -\frac{\hbar^2}{2m_e} \nabla_i^2 - \frac{Z e^2}{4\pi \varepsilon_0 r_i} \bigg) + \sum_{1 \le i < j \le Z} \frac{e^2}{4\pi \varepsilon_0 \lvert \mathbf{r}_i - \mathbf{r}_j \rvert} + H_\text{nucleus}, \] whose eigenstates \(\Psi_n\) correspond to quantized orbitals and energy levels \(E_n\) solving \[ H \Psi_n = E_n \Psi_n. \] Molecules and condensed phases arise when these atomic states combine via electromagnetic interactions into multi-atom bound states and extended many-body systems.
Portfolio as a wave function: density matrices instead of variance–covariance matrices
Below is a compact, code-adjacent sketch of the idea: in a quantum-flavored actuarial / MPT model, the classical variance–covariance matrix \(\Sigma\) is upgraded to a density matrix \(\rho\), and a portfolio is treated as a wave function \(|\psi\rangle\). This mirrors what you might simulate with Stan, but in linear-algebra form.
Classical MPT / actuarial notation
// n assets, vector of random returns R
// mean vector μ, variance–covariance matrix Σ
E[R] = μ // n×1
Cov(R) = Σ // n×n (symmetric, PSD)
// portfolio weights (deterministic)
vector[n] w;
real R_p = dot_product(w, R); // portfolio return
real mean_p = dot_product(w, μ);
real var_p = quad_form(Σ, w); // w^T Σ wLaTeX form: \( \mathbb{E}[R] = \mu \), \( \operatorname{Cov}(R) = \Sigma \), \( R_p = w^\top R \), \( \mathbb{E}[R_p] = w^\top \mu \), \( \operatorname{Var}(R_p) = w^\top \Sigma w \).
\( \mathbb{E}[R] = \mu \), \( \operatorname{Cov}(R) = \Sigma \), \( R_p = w^\top R \), \( \mathbb{E}[R_p] = w^\top \mu \), \( \operatorname{Var}(R_p) = w^\top \Sigma w \).
Quantum-style upgrade
We now re-interpret these same objects in a Hilbert-space way:
- Basis states \(|e_i\rangle\): one-hot exposure to asset \(i\).
- Portfolio wave function \(|\psi\rangle = \sum_i \psi_i |e_i\rangle\) with \(\sum_i |\psi_i|^2 = 1\).
- Density matrix (pure state) \(\rho = |\psi\rangle\langle\psi|\).
- Return operator \(\hat R\) with components \(\hat R |e_i\rangle = R_i |e_i\rangle\) in the simplest diagonal case.
In code-flavored pseudomath:
// amplitudes ψ (complex allowed), normalized
complex psi[n];
// density matrix ρ_ij = ψ_i ψ*_j
complex rho[n, n] = outer_product(psi, conj(psi));
// return operator R̂ (for illustration, take it diagonal)
real R_vals[n]; // possible asset returns
complex R_op[n, n];
for (i in 1:n) {
for (j in 1:n) R_op[i,j] = (i == j) ? R_vals[i] : 0;
}
// quantum expectation of portfolio return
real R_vals[n]; // possible asset returns
complex R_op[n, n];
for (i in 1:n) {
for (j in 1:n) {
R_op[i,j] = (i == j) ? R_vals[i] : 0;
}
}
// quantum expectation of portfolio return
complex mean_p_q = trace(rho * R_op); // ≈ classical w^T μ
Mathematically,
ρ = |ψ><ψ| <R̂>_ψ = <ψ| R̂ |ψ> = Tr(ρ R̂)
LaTeX form: \( \rho = |\psi\rangle\langle\psi| \), \( \langle \hat R \rangle_\psi = \langle \psi|\hat R|\psi\rangle = \operatorname{Tr}(\rho \hat R) \).
\( \rho = |\psi\rangle\langle\psi| \), \( \langle \hat R \rangle_\psi = \langle \psi|\hat R|\psi\rangle = \operatorname{Tr}(\rho \hat R) \).
If \(\hat R\) is diagonal in the \(|e_i\rangle\) basis and we ignore phases, \(|\psi_i|^2\) plays the same role as classical weights \(w_i\). But once off-diagonal elements are allowed, \(\rho\) carries richer cross-asset structure than \(\Sigma\) alone.
Stan-style simulation vs Schrödinger-style evolution
Stan would typically simulate posterior draws of parameters \(\theta\) (e.g., drifts, vols, correlations) and then simulate returns:
// very schematic Stan pseudo-flow
for (m in 1:M) {
θ[m] ~ posterior(· | data); // parameters: μ[m], Σ[m], etc.
R[m] ~ mvnormal(μ[m], Σ[m]); // draw returns
R_p[m] = dot_product(w, R[m]);
}
// compute empirical mean/var/VaR of R_p from samplesIn the wave-function view, instead of sampling many \(\theta\), we evolve the state itself under a Hamiltonian \(\hat H\) that encodes drift/volatility/market structure:
// time evolution of portfolio state ψ_t
// i ℏ d|ψ_t>/dt = Ĥ |ψ_t>
psi_t+Δt ≈ exp(-i Δt Ĥ / ℏ) * psi_t;
// at horizon T, density matrix ρ_T = |ψ_T><ψ_T|
// expected payoff under operator Π̂
price_0 ≈ discount * trace(ρ_T * Π̂);This is the code-level version of “instead of running Stan simulations over parameter space, we let the whole portfolio turn into a wave function and flow under \(\hat H\).”
Black–Scholes as the one-asset limit
For a single risky asset in Black–Scholes, under the risk-neutral measure we have
dS_t = r S_t dt + σ S_t dW_t
The price \(V(S,t)\) of a European claim satisfies
∂V/∂t + (1/2) σ^2 S^2 ∂^2V/∂S^2 + r S ∂V/∂S - r V = 0
After changing variables \(x = \ln S\) and switching to forward time \(τ = T - t\), this maps to a heat equation which can be written in imaginary time as
∂φ/∂τ = (1/2) σ^2 ∂^2φ/∂x^2 - V_eff(x) φ
Under a Wick rotation \(τ → i t\), this resembles a Schrödinger equation
i ℏ ∂ψ/∂t = Ĥ ψ
with \(\hat H\) containing a kinetic term (diffusion from \(σ\)) plus an effective potential. In this limit:
- Classical risk-neutral density \(f_{S_T}(s)\) ↔ \(|\psi(s,T)|^2\).
- Option price \(V_0\) ↔ expectation \(\langle \psi_T| \hat \Pi |\psi_T\rangle\).
So Black–Scholes is already half-way to the quantum formalism: it evolves distributions through a linear PDE. The density-matrix formulation just generalizes this to multiple coupled assets and richer dependence than a single \(\Sigma\) can conveniently express.
Classical vs Quantum Computer: pseudo-code views
This section strips away hardware details and shows, in pseudo‑code, how a conventional laptop and a quantum processor “feel” different as machines.
Conventional computer (motherboard + CPU + RAM)
// physical picture
// --------------------------------------------------
// motherboard: connects CPU, RAM, storage, peripherals
// CPU: executes instructions sequentially (with some parallelism)
// RAM: holds bits (0 or 1) for active programs
machine ClassicalComputer {
Motherboard board;
CPU cpu;
RAM ram;
Storage disk;
}
// run a program
function run_classical(program P, input bits_in[]):
// 1. load code and data into RAM
ram.load(P.code)
ram.load(bits_in)
// 2. CPU executes instructions one by one
while cpu.instruction_pointer not at END(P):
instr = ram.fetch(cpu.instruction_pointer)
cpu.execute(instr, ram)
cpu.instruction_pointer++
// 3. read out output bits from RAM
bits_out = ram.read(P.output_region)
return bits_outQuantum processor (QPU + classical control computer)
// physical picture
// --------------------------------------------------
// classical control computer: compiles code, sends pulses
// quantum processing unit (QPU): array of qubits on a chip
// cryostat: keeps QPU near absolute zero
machine QuantumComputer {
ClassicalControl ctrl; // compiler, schedulers
QuantumProcessingUnit qpu; // qubits + control lines
}
// high-level quantum run
function run_quantum(circuit C, classical_input bits_in[]):
// 1. classical pre-processing
// e.g., encode bits_in into initial qubit states
compiled_pulses = ctrl.compile(C, bits_in)
// 2. upload pulse schedule to QPU
qpu.load(compiled_pulses)
// 3. apply quantum operations (unitaries)
qpu.apply_pulses()
// internally, each gate is a unitary U on |ψ>:
// |ψ_new> = U |ψ_old>
// 4. measure qubits
measurement_record = qpu.measure_all() // collapses |ψ> → classical bits
// 5. classical post-processing
result = ctrl.post_process(measurement_record)
return resultConceptually:
- The classical CPU walks through a list of instructions, flipping bits in RAM.
- The QPU evolves a joint quantum state \(|\psi\rangle\) of many qubits by applying gates (unitaries), then collapses that state to classical bits via measurement.
Same abstract computation, two execution models
Imagine we want to compute the parity (even/odd) of \(N\) bits.
Classical laptop parity
function parity_classical(bits[]):
acc = 0
for b in bits:
acc = acc XOR b
return acc // 0 = even, 1 = oddQuantum parity sketch (conceptual)
function parity_quantum(bits[]):
// 1. encode bits into computational basis states
// |b_1 b_2 ... b_N>
|ψ> = |b_1 b_2 ... b_N>
// 2. use a circuit of CNOTs to copy global parity into an ancilla qubit
// |ψ, 0> → |ψ, parity(bits)>
for i in 1..N:
CNOT(control = qubit_i, target = ancilla)
// 3. measure only the ancilla qubit
result = measure(ancilla)
return result // 0 = even, 1 = oddOn such a small task, the quantum route is not “better” than the classical one—it is just a different physical implementation of the same logical function. Real quantum advantage typically appears in problems that exploit superposition and interference over huge state spaces.
Deep dive: complexity classes BPP vs BQP
If you like big‑picture theory, the usual cartoon is:
- BPP (“bounded‑error probabilistic polynomial time”): problems efficiently solvable by a classical computer that can flip random bits, with error probability \(< 1/3\) (or any fixed constant < 1/2).
- BQP (“bounded‑error quantum polynomial time”): problems efficiently solvable by a quantum computer, again with error probability \(< 1/3\).
Formally, a language \(L\) is in BQP if there is a family of quantum circuits \(\{C_n\}\) of size polynomial in \(n\) such that for all inputs \(x\) of length \(n\):
- If \(x \in L\), then \(\Pr[C_n(x) = 1] \ge 2/3\).
- If \(x \notin L\), then \(\Pr[C_n(x) = 1] \le 1/3\).
We know that \(\text{BPP} \subseteq \text{BQP}\) (quantum can simulate classical randomness), but we do not know whether \(\text{BPP} = \text{BQP}\) or \(\text{BPP} \subsetneq \text{BQP}\). Evidence from Shor’s algorithm and other candidates strongly suggests that \(\text{BQP}\) is strictly more powerful than \(\text{BPP}\) for some natural problems (like factoring large integers), but there is no proof yet.
Hardware analogy table: consumer laptop vs quantum processor
The numbers below are intentionally rounded, order-of-magnitude style, to give intuition. Real devices vary wildly; treat these as cartoon benchmarks, not spec sheets.

| Device | Rough scale | Operation type | Throughput (back‑of‑envelope) | Notes |
|---|---|---|---|---|
| Consumer laptop CPU (1 core) | ~3 GHz clock | Classical bit ops | ~3×109 simple ops/s | One scalar instruction stream; vector units add more parallelism. |
| Consumer laptop (8 cores, SIMD) | 8 cores × 3 GHz × 128‑bit SIMD | Classical bit/word ops | ~1011–1012 basic ops/s | Depends heavily on workload and vectorization. |
| Mid‑range GPU in a laptop | ~103–104 cores | Classical float ops | ~1012–1013 FLOP/s peak | Great for dense linear algebra and ML training. |
| Small noisy quantum processor | ~50–100 physical qubits | Quantum gates on 2N-dim state | ~103–104 2‑qubit gates per run before noise | Each gate acts on amplitudes of 2N basis states in superposition. |
| Hypothetical fault‑tolerant QPU | ~106 physical qubits → 103 logical | Error‑corrected quantum circuits | ~109–1012 logical gates over long algorithms | Aimed at large chemistry, optimization, or cryptographic tasks. |
"How many laptops equal one quantum processor?" (cartoon answers)
The trick is: you cannot fairly compare them just by counting operations per second, because a quantum gate on \(N\) qubits simultaneously transforms amplitudes across \(2^N\) basis states. Still, you can get a feeling by asking:
Example 1: simulating 30 qubits on laptops
- State vector size: \(2^{30} \approx 10^9\) complex amplitudes.
- One layer of single‑qubit gates might touch all \(10^9\) amplitudes.
- A single good laptop GPU at ~1012 FLOP/s can simulate ~103 such layers per second in theory, but memory bandwidth and overhead reduce this a lot.
A small physical QPU with 30–40 qubits applies the same logical layer directly in hardware; it is as if you had a cluster of hundreds to thousands of laptops working together to update all amplitudes every gate.
Example 2: 50‑qubit state
- State vector size: \(2^{50} \approx 10^{15}\) complex amplitudes.
- Storing this naively (16 bytes per complex) needs ~16 petabytes of RAM.
- Even a supercomputer cluster of millions of consumer‑class laptops would struggle to hold and update this in full generality.
So for generic 50‑qubit circuits, one real QPU is morally comparable to an enormous classical cluster. For structured problems, clever classical algorithms can do much better—that’s why the “how many laptops” question has no single honest number.
Very rough equivalence table (for mental models only)
| Quantum device (noisy) | State size 2N | Naive RAM to store state | Approx. # of 16 GB laptops for RAM only |
|---|---|---|---|
| 20‑qubit QPU | ~106 | ~16 MB | < 1 laptop (fits easily) |
| 30‑qubit QPU | ~109 | ~16 GB | ~1 laptop (RAM is tight but possible) |
| 40‑qubit QPU | ~1012 | ~16 TB | ~1000 laptops (each 16 GB) |
| 50‑qubit QPU | ~1015 | ~16 PB | ~1,000,000 laptops (each 16 GB) |
This table only matches memory capacity, not speed. But it gives a rough intuition: once you pass ~40–50 entangled qubits in a generic circuit, brute‑force classical simulation starts looking like “you’d need an absurd number of consumer laptops.”
Trusted Expertise
✅ Sam Castillo has successfully completed the AI Fundamentals course by Google via Coursera. Whether you are building a predictive model or deploying LLMs, our methodologies align with industry-leading standards to guarantee accuracy, trust, and high performance.
Project Alpha: The Post-Quantum Intranet
Test drive our raw, uncensored AI framework: Dolphin Mistral, running fully autonomously on an isolated server node based in Alaska.
As we approach a new era of computational scaling, traditional HTTPS and SSL-based web encryption will inevitably become obsolete against quantum decryption methods. To prepare, we are actively developing the foundational layers of a true "digital moat." At its core, this architecture operates as a machine-to-machine blockchain intranet—a decentralized, structural anti-virus network that securely handshakes autonomous LLMs and critical systems without relying on legacy, vulnerable internet channels.
Go Premium
Exploratory Data Analysis
Clean, summarize, and visualize your data to uncover trends and insights quickly.
Predictive Model Algorithm
This foundation model has been pre-trained, and already validated. Uses our recipe for maximum productivity. Only supervised (no clustering)
LLM and SQL Pipeline
Integrate large language models with SQL databases for advanced data querying and analysis.
A business invoice will be emailed after purchase.